
GCSトリガーのデータインポートの背景
Google Cloudでデータ取込のパイプラインを開発しました。
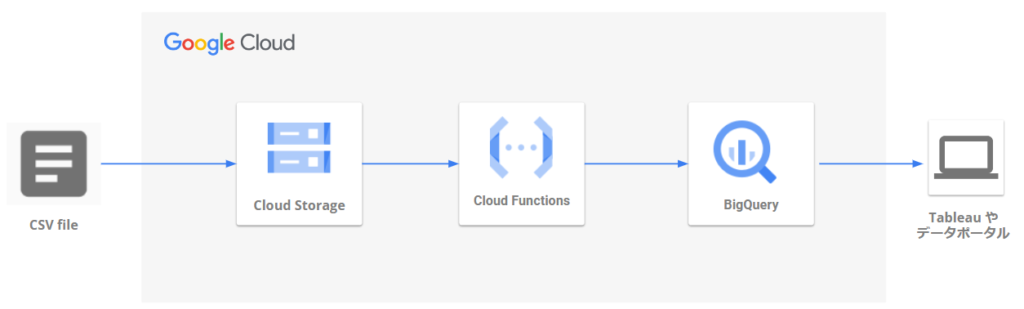
その際に、Cloud Storageにデータが配置されたことをトリガーにBigQueryにデータ取込を実行する処理を作りました。
そちらのコードが調べても意外と出てこなかったのでサンプルコードとアーキテクチャをまとめてみました。
GCSトリガーを使用してやりたかったこと
- Google Cloud環境にて、 csvファイル取り込み→データ加工→可視化→分析 を自動で出来るようにしたかった
GCSトリガーで実現したこと
- Cloud Functionsで処理を実行する(言語:python)
- Cloud Storageにcsvファイルを配置したことをトリガーにBigQueryにデータインポートする&取り込むファイルをファイル名で判定する
- 取り込んだ日本語が文字化けしないようcsvファイルはUTF-8を指定する
Cloud Functionsとは、サーバーレスにアプリが実行できるサービスです。
例えば、Cloud Functionsにコードを記述することでCloud StorageのデータをBigQueryに取り込むことやBigQueryのデータを加工することが可能です。ファイル配置や時間指定のトリガーが設定できます。MAX9分でタイムアウトするので、大規模な処理には向かないかもしれません。
GCSトリガーのアーキテクチャ
Cloud Functionsに記述したコードサンプル
下記のコードをCloud Functionsのpythonファイルに記述しました。
※青字部分はコメント
※先に取込ファイルとカラム名・データ型を合わせたテーブルをBigqueryで作成しておく
from google.cloud import bigquery
client = bigquery.Client()
def main(data, context):
# Cloud Storageに配置されたファイル情報の取得
bucket_name = data["bucket"]
file_name = data["name"]
uri = 'gs://{}/{}'.format(bucket_name, file_name)
# インポートしたいcsvファイル名に含まれる文字列を指定
# ⇔取り込むファイル名には毎回 csv_file で指定した文字列を含む必要がある
csv_file = "ファイル名に含まれる文字列"
# データ更新先のBigquery内データセット名・テーブル名を指定
# Cloud Storageに配置されたファイル名が違う場合は処理終了となる
dataset_id = "取込先のBQのデータセット名"
if csv_file in file_name:
table_id = "取込先のBQのテーブル名"
else:
print('end')
return
dataset_ref = client.dataset(dataset_id)
# スキーマ定義(列1~3が取込先のBQのカラム、必要に応じ増やす)
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("列1", "STRING"),
bigquery.SchemaField("列2", "STRING"),
bigquery.SchemaField("列3", "STRING")
]
)
job_config.source_format = bigquery.SourceFormat.CSV
job_config.skip_leading_rows=1 ←ヘッダーとばすの意味
job_config.write_disposition = 'WRITE_TRUNCATE' ←テーブルをrepalaceするの意味
# BQへのロードJOB(このままでOK)
load_job = client.load_table_from_uri(
uri, dataset_ref.table(table_id), job_config=job_config
)
load_job.result()
print('success load')Google Cloud関連記事
- データ分析基盤のアーキテクチャ全体を記載してしております
- Cloud FunctionsでのBigqueryへのSQL実行 と組み合わせるとBigQueryへの取込に加えてBigQuery内のテーブルへのクエリ実行ができます
参考になれば幸いです☕


コメント